01
Feb 2017
My first Machine Learning project: Using Naive Bayes to classify tweets
|
Tags |
On Computer Technology
Source code: https://gist.github.com/yanhan/d9061c9575d14228d2a9ecc9519a55aa
Before we go into the main content of this post, I have a confession to make - it’s pretty damned hard to get started with Machine Learning if you’re not doing it on the job and if you don’t happen to have some problem to solve (and have the appropriate data for it). One of the main hurdles I’ve faced is that after picking up some fundamentals, Machine Learning knowledge is like this hammer but there aren’t many suitable nails in sight, probably because of my lack of experience; a lot of problems also seem very, very tough. This post is my latest attempt to build up my skills in it - through some hands on experience on “real-world” data sets. Hopefully this trend keeps up and I’ll have many more projects under my belt over the course of the year.
Recently, I’ve finished reading John Foreman’s Data Smart and got quite inspired to try out some techniques in there. I spent an entire afternoon brainstorming about some project ideas. One of them is, why not do a variant of what’s covered in Data Smart chapter 3, which is, to use Naive Bayes to classify tweets? Except that, we’ll be using a programming language instead of Excel (thank goodness).
Alright, we’ve decided on the algorithm - Naive Bayes. To make things simple, we will build a binary class classifier, just like in the book. So, what kind of tweets? The best kind of tweets are probably those involving some word with ambiguous meaning. This word may or may not be used as a hashtag in the tweets. The word ‘react’ was one of the first which came to my mind - after all, it is used in conventional speech / writing and is the name of a popular JavaScript framework, so the same word stands for two very distinct things/meanings. A human reading the tweets should not have much issue labelling the data but more importantly, these 2 attributes of the word ‘react’ should garner a sufficiently large number of tweets for both classes.
I wish I could say that there was a data set that I just downloaded from somewhere or I used the Twitter API to do this, but I did a search on Twitter and manually copy and pasted tweets into 2 files, one for tweets about the React framework and the other containing tweets that are not about the React framework. For each class, I collected 250 tweets and all / most of them contain the word ‘react’ or ‘React’. This was a very painful and laborious process that took a few hours to complete. In particular, most tweets about the React JS framework do not contain the word ‘react’ or ‘React’ but contain ‘ReactJS’ (maybe in a different case), so it took a long time for me to find suitable tweets.
For each class, I shuffled the 250 tweets and partitioned them into a training set of 180 tweets (72% of the data) and a test set of 70 tweets (28% of the data).
This is a toy problem and it is extremely easy to classify tweets about React JS correctly - in fact we don’t need machine learning to do it. During the process of gathering the data, other than the fact that most tweets about React JS contain the word ReactJS in some kind of case variant or use the hashtag #ReactJS, they typically don’t use the word react and even if they do, it is almost always spelt React with an uppercase R instead of react. Whereas in tweets not about the React JS framework, we don’t see the uppercase React - it is always react. Ok, to make things more fun, we lowercase everything.
On the #ReactJS hashtag - by summing the token counts, we see that other than the token react, the next most common occurring token in the training set is #reactjs at 115 counts, followed by #javascript at 61 counts. Again, to make things more fun, we discard these two tokens.
There are 2 implementations: one hand-coded Naive Bayes implementation and one using scikit-learn.
For the hand-coded implementation, we follow most of the implementation in Data Smart. For each tweet, we first replace all occurrences of ., :, ?, !, ;, , which are followed by a space character with a single space character. Then we split on whitespace and reject all tokens with three characters or less, along with the tokens #reactjs and #javascript. We train 2 classifiers - one for recognizing tweets about React JS and the other for recognizing tweets not about React JS. Instead of the additive smoothing method covered in the book (which adds 1 to the count for every token), we use the Additive smoothing covered on Wikipedia and this Cross Validated question:
$$P(token | class) = \frac{x_i + \alpha}{N + \alpha * |V|} $$
where \(x_i\) is the token count in the class, \(\alpha = 1\), \( N \) is the sum of all token counts in the given class, and \( |V| \) is the size of the vocabulary in the entire training set (regardless of class). This is identical to the formula in the Cross Validated question, except that it doesn’t contain an additional \( + 1 \) in the denominator.
To handle tokens which are not present in the training set but present in the test set, we default to using this probability:
$$P(unseen\ token | class) = \frac{1}{N + |V|}$$
When passed a tweet, each classifier computes the sum of the log likelihood of each token in the tweet. We pass the tweet to both classifiers and compare the two log probabilities - the higher one wins and we say that the tweet belongs to that class.
The confusion matrix is as follows:
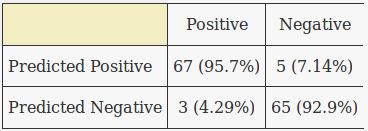
Looks pretty good.
Originally, I didn’t want to do this because this is just a toy project but, since I’m doing it already, might as well figure out how to implement Naive Bayes using scikit-learn on something simple like this.
After reading some stuff from the following links in the awesome scikit-learn documentation:
I figured out how to implement something similar to our hand-rolled Naive Bayes classifier using scikit-learn. Instead of using CountVectorizer, I decided to use HashingVectorizer. The hardest part in this implementation is to figure out how to use the HashingVectorizer. Eventually, it came down to this:
stop_words = list(
set(
sklearn.feature_extraction.text.ENGLISH_STOP_WORDS
).union(_BANNED_TOKENS)
)
vectorizer = HashingVectorizer(
stop_words=stop_words,
token_pattern=r"""\b\w\w\w\w+\b""",
norm=None,
non_negative=True,
)
We needed to add the stopwords #reactjs and #javascript to the default list of stopwords that the HashingVectorizer was using. A little googling yielded this useful answer. By default, HashingVectorizer uses the u'(?u)\b\w\w+\b' regex which captures any token of length 2 or more, but we only want tokens which are at least length 4, so we used token_pattern=r"""\b\w\w\w\w+\b""" to override that setting. We also didn’t want any normalization (default is 'l2') and we didn’t want any non-negative values - just raw counts.
We used the HashingVectorizer.transform method to transform all the training tweets into a sparse matrix, and fed that to sklearn.naive_bayes.MultinomialNB via its fit method. To evaluate this model on our test data, we need to use the HashingVectorizer to transform the test data, then pass them to the trained Naive Bayes model.
The confusion matrix for the scikit-learn Multinomial Naive Bayes model:
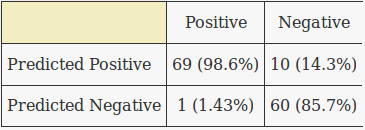
While this classifier performs better than our hand-rolled classifier for tweets about ReactJS, it performs worse for tweets that are not about ReactJS.

The number 1895 refers to the size of the vocabulary for the entire training set (both tweets about React JS and not about React JS). The log probability for an unseen token is higher for the React JS model as compared to the non React JS model. The pitfall is that a tweet which consists entirely of unseen tokens will favor the React JS model - most likely that tweet is not about React JS, since most tweets about React JS will have some variant of the #reactjs hashtag which will exist in the training set.
For the MultinomialNB model, the numbers are -13.86442357 for a non React JS tweet and -13.86489007 for a React JS tweet. A much smaller discrepancy that slightly favors the non React JS class.
For the first tweet, the only tokens that are counted are like, over, react, http://buff.ly/2jWKpzJ and #vuejs. Among those, only #vuejs has predictive power, since Vue.js is a JavaScript framework. However, the token #vuejs does not occur in the training set. So it is understandable that this tweet is misclassified.
It is a similar story for the second tweet, with only JS... being the token with predictive power. However, that doesn’t occur in the training set.
For the final tweet, the only token with predictive power is "react.js" (notice the quotes), but the presence of the quotes probably screwed things up.
Which is pretty curious, since the vectorizer correctly tokenizes "React.js" into the token react.js.
Notice that all the false positives for the Naive Bayes model are also false positives for the MultinomialNB model. If there’s one thing I can say straight off the bat about these false positives, it is this - they are about pretty different things - there is a tweet about star wars, a tweet about ants, etc. This is a stark contrast to the tweets about ReactJS, which are well, about ReactJS. But all these is just guesswork - let’s look at more concrete stuff.
For the tweet Why I like Vue over React - http://buff.ly/2jWKpzJ #vuejs #reactjs
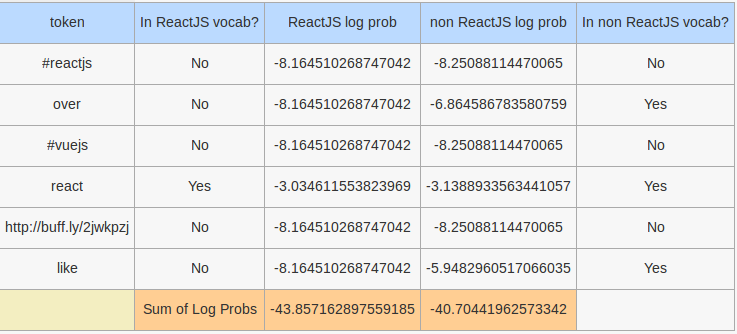
The main culprits are the tokens over and like. over is a stop word for scikit learn and its removal would have helped things slightly, but like is not a stop word and its relatively high log probability (compared to the other tokens which do not appear in the vocabulary) means that this tweet will still be incorrectly classified. Note that this tweet is not a false negative for the MultinomialNB model - some painstaking investigation into the log probabilities of the features of the MultinomialNB model revealed that the reactjs token greatly favored the React JS model and the react and http tokens slightly favored the React JS model; the other log probabilities are about even except for the token like favoring the non React JS model. Log probabilities given by the MultinomialNB model as follows:
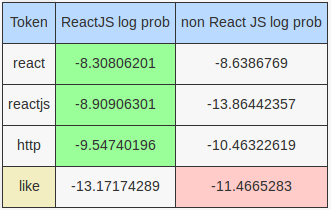
For the tweet The power of React JS... http://catchoftheday.wesbos.com/store/lazy-glamorous-knives …
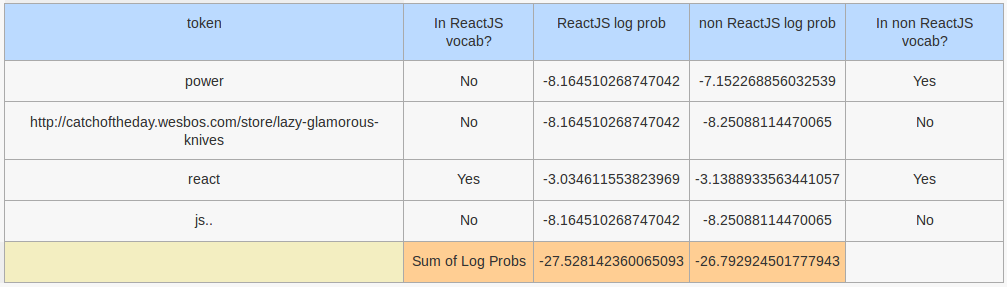
The culprit is the token power, which appears twice in the training set for non reactjs tweets but does not appear in the training set for reactjs tweets. Note that this tweet is correctly classified by the MultinomialNB model - most of the log probabilities for the tokens are pretty even and the difference makers for the React JS model are the tokens http, wesbos (there was an occurrence of @wesbos in the training set and after the processing by HashingVectorizer it became wesbos) and store (appeared once in training set) - notice that these are all tokens created as a result of removing all the punctuation in the URL and treating them just like whitespace. Seems like in a bag of words model, there may be more value chopping up URLs on top of leaving them as they are or maybe even as opposed to leaving them as they are. Log probabilities given by the MultinomialNB as follows:
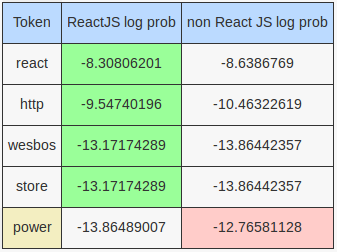
For the tweet these "google trends" charts can show almost whatever you want. people search for "React" rather than "React.js" http://image.prntscr.com/image/42ff33c9b0da42ef8084f45a647ccc00.png …
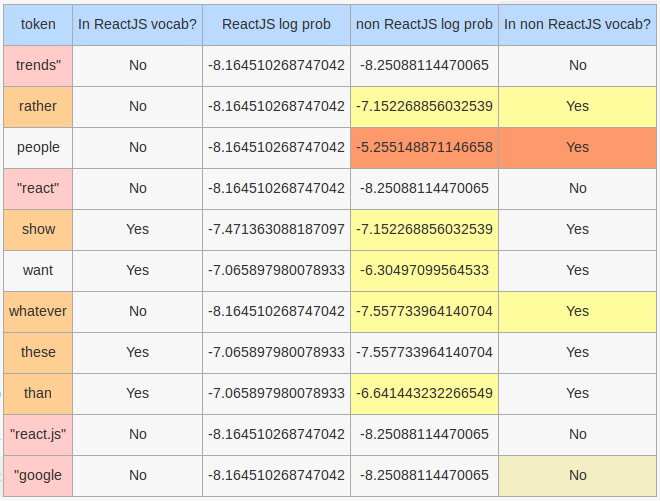
This is a rather long tweet so I am only showing some of the more interesting tokens here. First, the errors we made from tokenization - trends", "react", "react.js", "google; these are highlighted in pink. In a larger data set, these might have affected results more because they will be unified with the correct tokens. In particular, the token react.js will favor the React JS model.
There are 5 stop words here, namely: rather, show, whatever, these, than. These would have been removed by the a scikit learn model using the default English stop words. Their presence in classification favors the non React JS model, which contains more of these tokens with the exception of these.
Finally, the tokens people and want, which are neither stop words nor incorrect tokens. Especially people - it greatly favors the non React JS model.
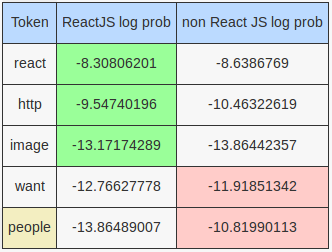
This tweet is also incorrectly classified by the MultinomialNB model. The HashingVectorizer will produce the following tokens: google, trends, charts, want, people, search, react, http, image, prntscr, 42ff33c9b0da42ef8084f45a647ccc00. Of these, react, http and image give a slight edge to the React JS model, but it is not sufficient to counter the effect of the tokens want and especially people. The table below shows the log probabilities of these tokens given by the MultinomialNB model:
Tweet: i may not react but trust me i saw it
Our hand rolled model sees the tokens trust and react, both of which slightly favor the React JS model - it is a very similar story for the MultinomialNB model. It seems that very short tweets like this one and tweets which contain many stop words (only 2 out of 10 tokens here are meaningful) can be easily misclassified by a Naive Bayes model.
Tweet: Star Wars superfans (and one feisty Rebel soldier) react to #RogueOne. http://strw.rs/60138rHgt
More interesting log probabilities for hand rolled Naive Bayes model:
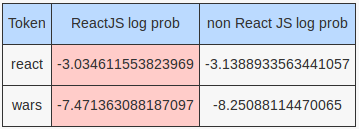
More interesting log probabilities for the MultinomialNB model:
Once again we see the flaw of a bag of words model - just because a token appears more frequently for documents of a given class doesn’t mean that a new document containing that token belongs to that class.
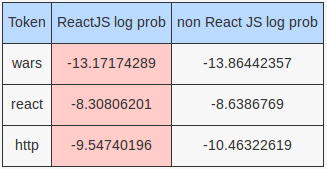
Tweet: Ants react to their infection by climbing up plants and sinking their mandibles into plant tissue
More interesting log probabilities for our hand rolled model:
Other than the above tokens, all the other tokens were unseen by both models. Recall that the log probability for an unseen token is about -8.1645 for the React JS model and -8.25088 for the non React JS model - these numbers add up to favor the React JS model, even if we remove all the stop words.
For the MultinomialNB model, it is the token react that made the big difference. All the other tokens are unseen in the training set, which gives a slight edge to the non React JS class but that was not enough to counter the effect of the react token.
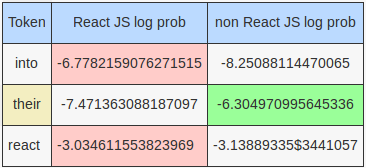
Tweet: @Khlil10x react to the NFL games
Another very short tweet.
Our hand rolled models sees the tokens @khlil10x, react and games. The only seen token is react, which favors the React JS model. Since log probs for unseen tokens are higher for the React JS model, everything favors the React JS model.
For the MultinomialNB model, it is again the token react that favored the React JS model. The other tokens Khlil10x and games are unseen and give a very very slight edge to the React JS model.
Tweet: Why ppl wud insult my father? Ppl wud react if I wud use my fathers name an absolute truth 2 impose n violate others basic rights.
More interesting log probabilities for hand rolled model:
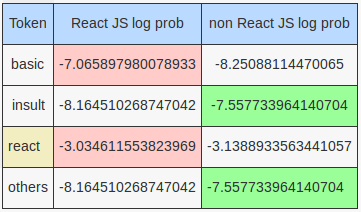
Even though insult and others gave an edge to the non React JS model, it wasn’t sufficient to offset the effects of the basic and react tokens along with 9 other unseen tokens.
More interesting log probabilities for MultinomialNB model:
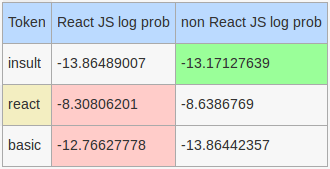
It is a similar situation for the MultinomialNB model with react and basic tilting the scales towards the React JS class.
The bigger question is, why does the MultinomialNB model perform worse than our hand rolled Naive Bayes model? The following tweets were correctly classified as negatives by our hand rolled Naive Bayes model but incorrectly classified by the MultinomialNB model:
Tweet: How everyone should react
After HashingVectorizer processes this tweet, the only remaining token is react, which favors the React JS class. How, everyone and should are stop words.
Stop words that will be considered by our hand rolled model: everyone, should
Log probabilities of the stop words for hand rolled classifiers:
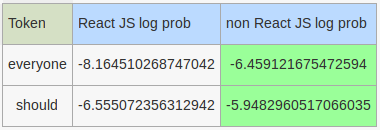
So it was indeed the log probabilities of stop words that influenced the outcome for our hand rolled classifiers.
Tweet: At this point, no one is believing 20% mexico surcharge is real. We'd have to abrogate NAFTA in total to do that. That why no market react.
More interesting log probabilities:
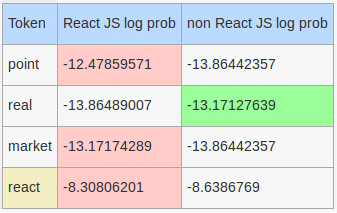
Stop words that will be considered by our hand rolled model: this, have, that
Log probabilities of stop words for hand rolled classifiers:
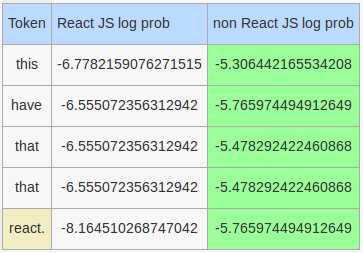
that appeared twice in this tweet and hence its log probability was counted twice. Notice the react. ending with a fullstop. Stop words definitely influenced the outcome for our hand rolled models.
Tweet: This is amazing. Jack Eichel's Dad & other Sabres parents in Nashville react to Eichel's game-winning goal in OT.
More interesting log probabilities:
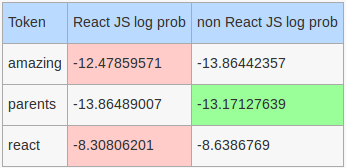
Stop words that will be considered by our hand rolled model: this, other
Log probabilities of stop words for hand rolled classifiers:
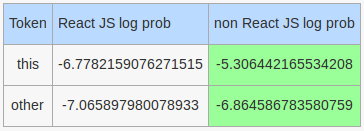
Again, stop words do influence the outcome in this case.
Tweet: Things to Consider: read the article & not just the headline before you react & retweet. Less exciting, but better for all.
More interesting log probabilities:
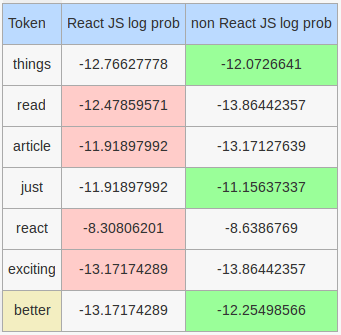
Stop words that will be considered by our hand rolled model: before, less
Log probabilities of stop words for hand rolled classifiers:
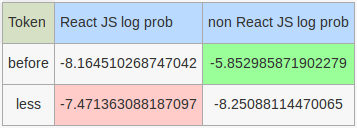
Tweet: If you're a #veteran, how do you react when someone calls you a hero? Here's my perspective on it http://ow.ly/EKQE308ex4i
More interesting log probabilities:

Stop words that will be considered by our hand rolled model: when, someone
Log probabilities of stop words for hand rolled classifiers:
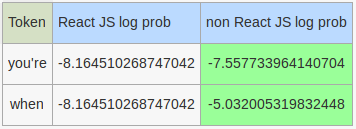
This is a more interesting case. While the stop word when tilts the scales towards the non React JS class, the token you're does so as well - this token does not exist in the vocabulary of the MultinomialNB classifier (it would have been chopped up into you and re and both discarded). Our hand rolled classifier also does not chop up the URL and so http isn’t a token for our hand rolled models.
From these 5 examples, we see that stop word removal by the HashingVectorizer introduced more false positives.
The Naive Bayes model works pretty well for a small data set and simple classification task like this one. For classification tasks involving text, it is probably a good starting point due to the simplicity of its implementation. As such, it makes a good baseline from which we can use to evaluate more sophisticated methods.
It is also pretty instructive to open up the model and figure out the reasons for misclassifications.
We summarize our findings here:
Even though this is a toy problem, we learnt how to do the following:
HashVectorizer with some customizationsAnd we got our hands dirty with machine learning outside of a course like environment or following instructions in a book / tutorial.
This also happens to be our first blog post in quite a while. To those reading this, Happy New Year folks!
Disclaimer: Opinions expressed on this blog are solely my own and do not express the views or opinions of my employer(s), past or present.
{kind=link}